

gRPC를 왜 써야했는지, 그리고 어떻게 구현해야하는지 알아봤습니다. 이제는 그래서 도대체 왜 gRPC가 빠른건지 이론적인 배경을 정리하겠습니다.
gRPC 성능의 핵심 이론
gRPC가 빠른 가장 큰 이유는 통신 계층의 개선(HTTP/2)과 데이터 표현 방식의 개선(Protocol Buffers)에 있습니다. HTTP/2가 제공하는 멀티플렉싱, 헤더 압축 등의 기능과, 프로토콜 버퍼를 통한 바이너리 데이터 직렬화가 결합되어 지연을 줄이고 처리량을 높입니다. 주요 이론적 요소를 정리하면 다음과 같습니다.
HTTP/2 멀티플렉싱
오늘날에 일반적인 웹 통신은 HTTP/1.1 버전을 따릅니다. 하지만 gRPC는 HTTP/2를 따르도록 되어 있으며, HTTP/2는 하나의 TCP 연결에서 동시에 여러 요청과 응답을 주고받을 수 있는 멀티플렉싱을 지원합니다.

이에 따라 이전 HTTP/1.1처럼 요청-응답을 순차적으로 처리하지 않아도 되므로 지연 시간이 크게 감소합니다. 즉, 클라이언트는 단일 연결로 다수의 요청을 병렬 전송하고 서버로부터 병렬 응답을 받아볼 수 있어 대기 시간이 줄어듭니다.
물론 HTTP/1.1 에서도 요청-응답을 비동기적으로 처리할 수 있도록, 즉 한번에 여러 요청을 처리할 수 있도록 Keep-Alive, pipelining 을 지원했지만 근본적은 해결책은 아니었기 때문에 HOL 블로킹(Head of line blocking)문제가 발생할 수 있으며, 다수의 proxy 서버들은 이 spec에 대응하지 못했습니다. 그에비해 HTTP/2 의 멀티플렉싱은 이러한 문제를 더 본질적으로 해결한 접근입니다.
HTTP/2 헤더 압축(HPACK)

HTTP/1.1에서는 매 요청마다 쿠키 등 반복적인 헤더들이 전송되어 불필요한 오버헤드가 많았습니다. HTTP/2에서는 헤더를 압축하고 중복을 제거하여 전송하기 때문에 대역폭 사용이 효율적이고 응답 속도가 개선됩니다. 예를 들어 gRPC는 HTTP/2 기반이므로 content-type, 권한 토큰 등의 헤더를 한 번만 보내거나 압축하여 반복 전송하지 않으므로, REST API 대비 패킷 크기가 줄고 처리 효율이 높아집니다.
Protocol Buffers 바이너리 직렬화
지금까지의 특성은 사실 HTTP/2를 이용하기 때문에 얻을 수 있는 이득이지 gRPC를 사용하기 때문에 얻는 이득이라고 보기 어렵습니다. 위의 성능상 이점은 클라이언트와 서버가 HTTP/2 위에서 REST로 통신을 해도 똑같으니까요. 하지만 gRPC는 proto buffer를 이용하여 바이너리 직렬화/역직렬화라는 추가적인 성능상 이득을 줍니다.
gRPC는 데이터 교환에 JSON 대신 Protocol Buffers(이하 ProtoBuf)를 사용합니다. ProtoBuf는 이진(binary) 포맷으로 데이터를 직렬화하기 때문에 JSON처럼 사람이 읽을 수 있는 텍스트 표현에 비해 데이터 크기가 작고 파싱 속도가 빠릅니다. ProtoBuf에서는 각 필드를 번호(Tag)로 식별하고 타입을 미리 정의하여 변환하므로, 키 이름과 구조를 일일이 문자열로 보내는 JSON에 비해 효율적인 인코딩/디코딩이 가능합니다.
데이터 중심 어플리케이션 설계의 저자 Martin Kleppmann는 자신의 블로그에서 이 부분을 정확히 설명했습니다.
# json 으로 이 데이터를 표현하면 82byte 지만
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
# proto 파일을 에서 메시지 포맷을 이렇게 정의하면 33byte 가 됩니다.
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}python code로 보자면, message/person.proto 파일을 기반으로 만들어진 pb2.py 파일에서 이진 포맷 데이터를 확인할 수 있습니다.
# pb/message/person.pb2.py
from google.protobuf import descriptor_pool as _descriptor_pool
...
# DESCRIPTOR 에 할당된 이진 데이터를 확인할 수 있습니다.
DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x14message/person.proto\x12\x06member\"H\n\x06Person\x12\x11\n\tuser_name\x18\x01 \x01(\t\x12\x18\n\x10\x66\x61vourite_number\x18\x02 \x01(\x03\x12\x11\n\tinterests\x18\x03 \x03(\tb\x06proto3')
...실험 결과: REST vs gRPC 성능 비교
공식 벤치마크
gRPC 공식문서에서는 Benchmark 에 대한 정보를 제공하고 있습니다. 심지어 Grafana로 만든 대시보드도 제공하고 있어서 정보를 얻기 정말 편합니다. 다만, REST 와 gRPC의 비교가 아니라 각 언어간 gRPC의 Latency 와 throughput 을 비교하는 자료여서 지금 알아보고자 하는 내용과는 달라서 깊이 알아보진 않겠습니다.
Payload 에 따른 비교
gRPC 특성상 다양한 클라이언트(언어)가 고려되어야 할것입니다. 다양한 벤치마크들 중 KTH의 학사학위 프로젝트에서 적절한 레퍼런스를 찾은듯 합니다.

Java, Python, Rust 언어에 대해서 요청횟수는 고정하고, payload 크기를 XS, S, M, L 으로 바꿔가며 실험한 결과를 발견했습니다. 초록부터 Appendix 이전가지 44 페이지 정도 되는 짧은 보고서이므로 다 읽어보는게 좋겠지만, 실험결과만 요역하자면 다음과 같습니다:



실험 결과에 따르면, Payload 크기가 클수록 gRPC의 성능이 REST 대비 일관되게 우수한 것으로 나타났습니다. Java, Python, Rust 세 언어 모두에서 동일한 경향이 확인되었으며, 특히 중간(M) 이상 크기의 메시지에서 gRPC가 확실한 우위를 보였습니다. 예를 들어 Java 환경에서는 protobuf로 인코딩된 메시지는 JSON 대비 56% 더 작은 크기를 가졌고, gRPC 서버는 REST보다 52% 더 높은 throughput 을 달성했습니다.
프로그래밍 언어에 따라 gRPC의 효율성은 다소 차이가 있었습니다. 실험에서는 Payload가 아주 커지는 경우(예: L)에는 Python의 gRPC 성능 향상폭이 다른 두 언어의 성능 향상 폭보다 굉장히 컸습니다. 반면 Payload가 작은 경우 RUST는 명확하게 REST 를 이용하는게 gRPC 보다 340% 더 높은 throughput을 보여주었습니다.
이러한 실험결과를 통해 얻을 수 있는 인사이트 아래와 같습니다:
- 항상 gRPC가 REST보다 나은것은 아니다. 전달하는 데이터 payload가 작다면 REST를 고려할수도 있다.
- 언어에따라 REST 대비 gRPC의 성능이 차이가 있다. 만약 성능상 차이가 크지 않다면 운영이 더 복잡해지는 gRPC를 굳이 도입하지 않을 수도 있다.
직접 실험하기
위의 실험도 충분히 재미있고 유용한 결과를 주지만 요청횟수에 따른 비교가 아쉽습니다. 더 오피셜하고 명확한 레퍼런스로는 "2021년에 작성된 관련 보고서" 가 있지만, 저는 접근할 수 없어서 직접 테스트하게 되었습니다.
원래는 더 현실적인 테스트를 위해 EC2 에 gRPC, REST 서버를 올리고 부하 테스트를 진행했지만, 제가 이용하는 네트워크망이 일반 가정용이어서 너무 느린 문제로 결국 localhost 테스트로 대체되었습니다.
이하의 내용은 github에서 코드를 내려받으셔서 직접 재현할 수 있습니다.
테스트 환경
- 서버 환경: MacBook Air 15, M3, 2024, RAM 24GB
- REST 서버: Starlette + Uvicorn (--workers=2)
- gRPC 서버: Python grpc.server(ThreadPoolExecutor(max_workers=10)), grpc.aio.server(...)
- 클라이언트: go ghz, hey
- Response Payload 크기: 14KB, 256KB (REST는 JSON, gRPC는 Protobuf)
- 부하 조건: 클라이언트: 50, 100개, 요청: 2000, 5000, 10,000
테스트 결과
부하조건을 다르게 줬지만, 결과적으로 저정도 부하 조건에는 각 프로토콜별로 유의미한 차이를 찾을 수 없습니다. raw 데이터는 구글 스프레드시트에 열어두었습니다.(raw data)
그래서 Payload 크기를 14KB, 256KB 로 고정했을때 클라이언트 100개가가 총 10,000개의 요청을 전달하는 케이스만 요약하였습니다.
14KB 조건:
위의 "Payload에 다른 비교"와 같은 결과가 나왔습니다. REST 가 전반적으로 gRPC, gRPC_aio 보다 적은 Latency 를 보여주 고 있습니다.
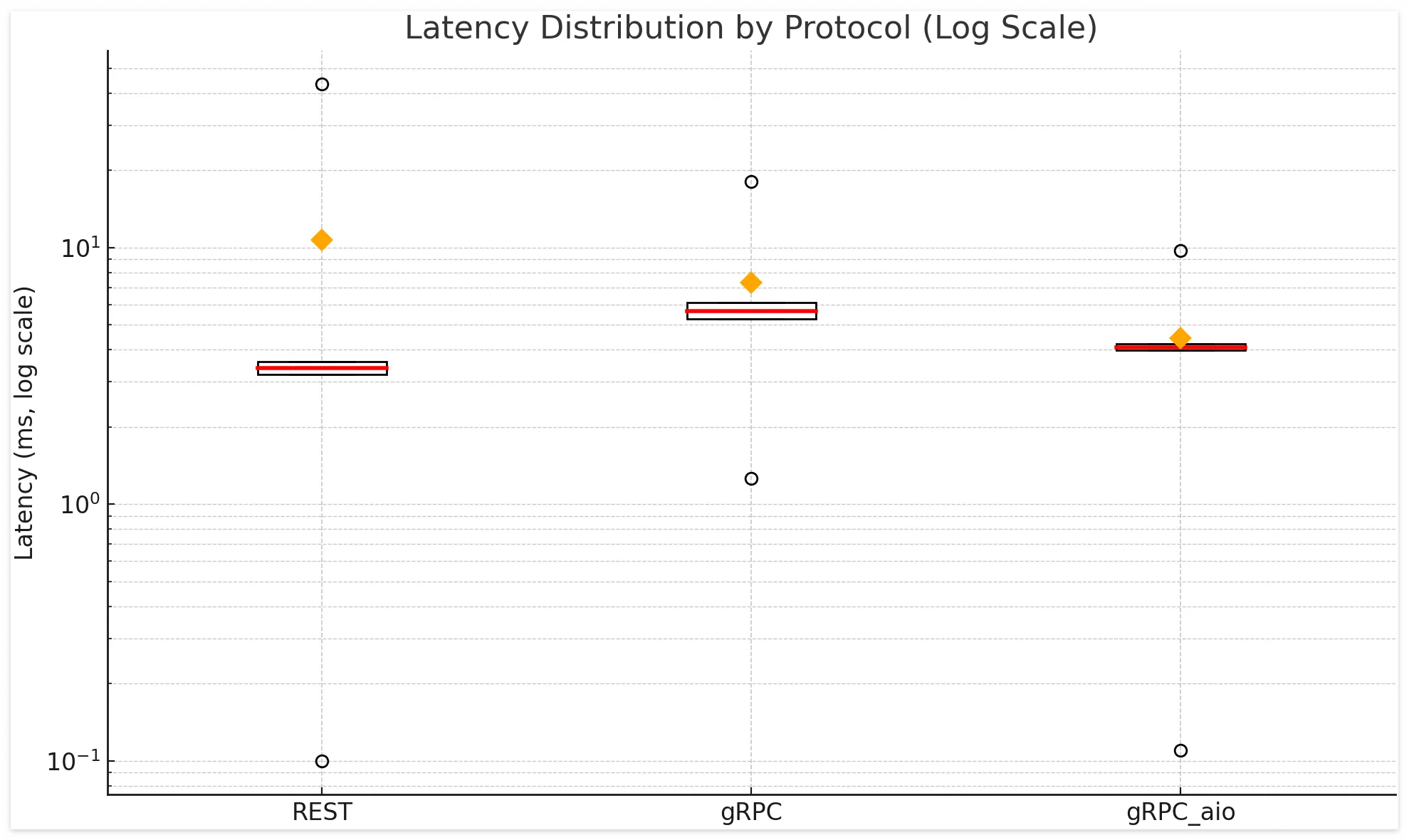
실제 median latency 로 비교를 해보자면 REST(3.4ms), gRPC(5.66ms), gRPC_aio(4.09ms) 로, REST 가 gRPC 보다 40%, gRPC_aio 보다는 16% 더 나은 성능을 보여주고 있습니다.
다만 99% percentile 에서의 안정성은 gRPC 가 REST 보다 뛰어났으며, 특히 aio 를 이용한 gRPC가 더 안정적인 모습을 보여주었습니다.
256KB 조건:
Payload 크기가 커지자 gRPC의 성능이 REST보다 나아지기 시작했습니다. 역시 aio를 이용한 gRPC 가 gRPC 보다 더 안정적이고 더 나은 성능을 보여주는 것이 확인되었습니다.

실제 median latency 로 비교를 해보자면 REST(22ms), gRPC(14.19ms), gRPC_aio(12.33ms) 로, REST 가 gRPC 보다 55%, gRPC_aio 보다는 78% 더 안좋은 성능을 보여주고 있습니다.
gRPC vs gRPC_aio
직접 벤치마크 테스트를 해보고는 스웨덴 학부생들이 했던 실험결과를 재확인하였습니다. 그런데 거기서 그치지 않고 추가로 흥미로운 결과과를 하나 확인했습니다. aio 를 이용한 gRPC가 일반 gRPC보다 단순 I/O 작업에서 더 좋은 성능(낮은 Latency)를 보여주고 있다는 것입니다.
gRPC는 Python Thread에 기반하여 동시성을 구현하고 있는것으로 추측됩니다. 그렇다면 Python Asyncio를 추가로 이용하는 grpc.aio 가 단순 I/O 작업에서는 더 나은 성능을 보여주는것은 당연할 것입니다.
따라서 일반적으로 I/O 가 중요한 작업이라면 gpc 보다는 grpc.aio 를 이용하는게 더 나은 선택일 것입니다. 다만 아직은 Python GIL을 이용하는게 기본 사양이므로 gRPC를 통해 일어나는 작업이 CPU Bound 하다면 무작정 grpc.aio를 이용하는건 지양해야할것입니다.
종합 결론
모두 Python에 대한 이야기입니다.
- localhost 환경에서 REST의 병렬처리 정도를 (warker)를 높인다면 요청 처리량에 있어서는 gRPC 와 유의미한 차이가 없음
- Payload가 일정수준 커질경우 gRPC가 REST 보다 더 나은 성능을 보여줌
- Payload 크기와 관계없이 항상 gRPC가 REST보다 더 안정적인 성능(저 낮은 Latency 편차)을 보여줌
실험 한계
- 테스트는 모두 localhost에서 진행되어 HTTP/2의 장점(멀티플렉싱, RTT 감소 등)은 반영되지 않음
- CPU 사용률, 메모리 프로파일링은 포함하지 않음 (추가 실험 대상)
참고
- What does multiplexing mean in HTTP/2, stackoverflow
- HTTP/1.x connection management, MDN
- http2 for web developers, cloudflare
- gRPC vs REST, .NET Benchmakr
- gRPC vs REST, A Comparative Study of REST and gRPC
'탐구 생활 > gRPC&Python' 카테고리의 다른 글
| Python gRPC (4) - gRPC gateway 에 대한 탐구 (0) | 2025.04.27 |
|---|---|
| Python gRPC (2) - 기본 구조와 python 구현 (0) | 2025.03.08 |
| Python gRPC (1) - 왜 gRPC 를 선택했나 (0) | 2025.03.08 |