1. Saga 패턴
모놀로식 아키텍처에서 단일 DB 를 사용하고 있다면 트랜잭션의 원자성과 일관성을 DBMS 수준에서 보장을 해준다. 따라서 데이터의 일관성을 유지하는게 어렵지 않다.
하지만 MSA 에서 여러 서비스의 서로 다른 DBMS 를 거쳐 영속화 해야하는 것은 흔한 일이다. 때문에 데이터 일관성 문제가 발생한다. 이러한 문제를 해결하기 위해 “서로다른 DBMS 의 트랜잭션을 논리적으로 묶을 필요”가 있었고 이를 위해 등장한 설계 패턴이 Saga 패턴이다. (마치 트랜잭션이 전파되는 것이 이야기가 전파되는것과 같다고 하여 Saga 라고 부른다)

Saga 패턴에서 트랜잭션을 논리적으로 묶는 주체는 어플리케이션이다. 위와 같이 트랜잭션이 실패했을 때 보상 트랜잭션(cancel) 을 호출 어플리케이션에 전달하고 트랜잭션 롤백 등 지정된 행위를 하게 만든다. 이 과정에서 일시적으로 데이터 정합이 깨져있을 수 있으나 “결과적 정합”을 보장한다.
위 그림은 단순히 트랜잭션 신호 전달만 도식화했을 뿐이다. 실제로 트랜잭션 성공(TransactionComplete) 혹은 실패(Cancel) 은 메시지 브로커를 통한 이벤트로 전달된다.
이러한 saga 패턴은 코레오그래피 기반 사가(Choreography-based Saga)와 오케스트레이션 기반 사가(Orchestration-based Saga) 등이 있다.
2. 코레오그래피 기반 사가(Choreography-based Saga)
코레오그래피 기반 사가는 아래의 그림과 같이 각 서비스간 메시지 브로커로 직접 결합된 형태이다.

서비스와 서비스를 메시지 브로커가 직접 중계하기 때문에 구현이 쉽다. 하지만,
트랜잭션 Saga 참가자가 많을 수록 트랜잭션 흐름이 복잡해지고 마이크로 서비스간 순환 종속이 발생할 수 있다. 또한 서비스가 발행, 소비 주체를 알고 있다고 가정하고 메시지를 설계한다면 서비스간 결합도가 높아진다는 부작용이 있다.
3. 오케스트레이션 기반 사가(Orchestration-based Saga)
오케스트레이션 기반 사가는 중앙 집중된 Saga Orchestration 이 saga 참여자들에게 어떤 로컬 트랜잭션에 참여해야 하는지 알려주는 형태이다.
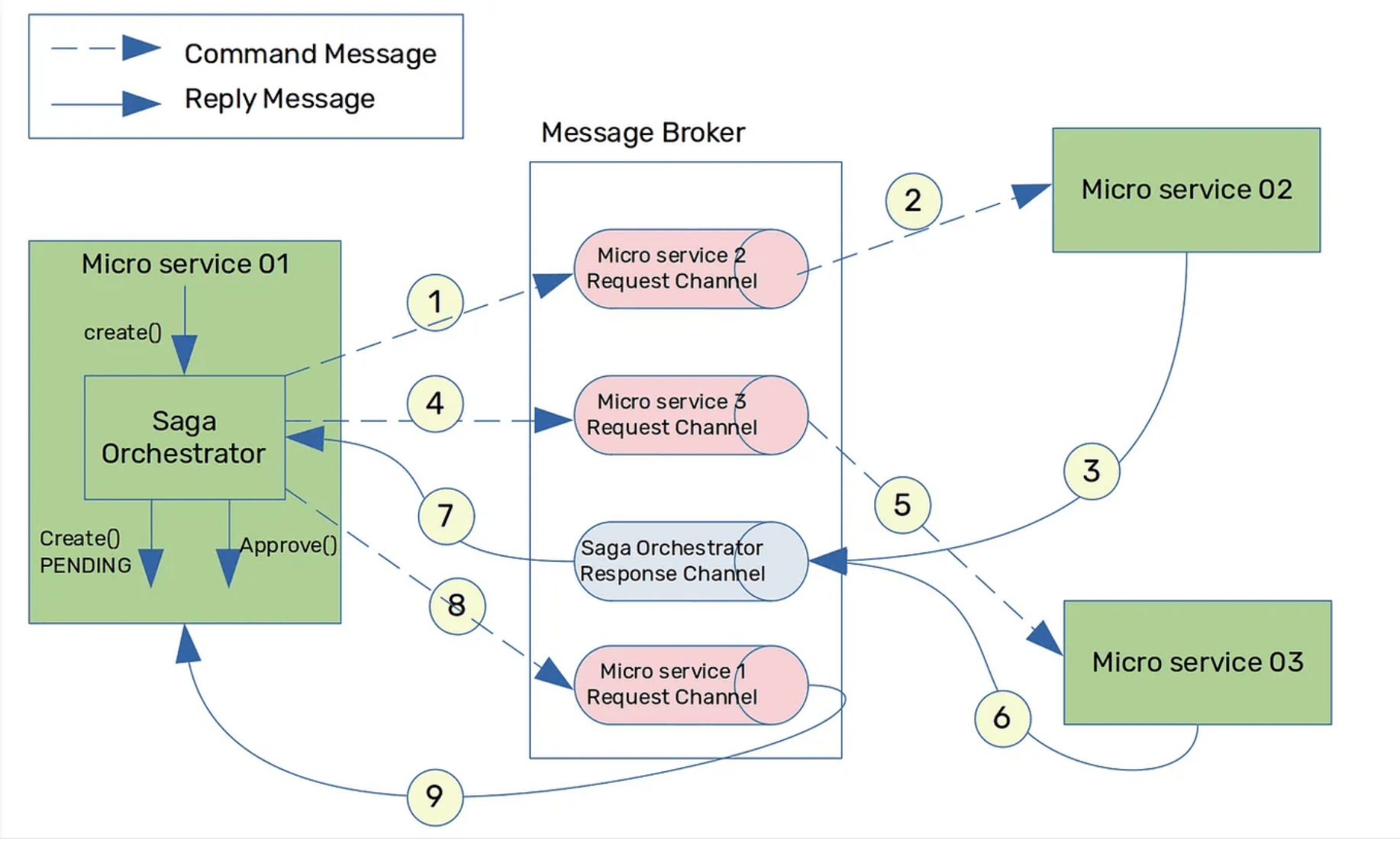
트랜잭션 흐름이 명확해지고 서비스간 결합도를 낮출 수 있다는 장점이 있지만,
오케스트레이터(Orchestrator) 가 실패했을 때 모든 트랜잭션 연계가 끊길 수 있다는 SPOF 문제가 있으며 서비스간 결합도는 낮아지지만 서비스와 오케스트레이터간 결합도가 높아진다는 단점있다. 이러한 이유로 유연성과 확장성이 낮아질 수 이다는 위험이 있다.
4. 보장되지 않은 영속화 순서, CorrelationID
아래와 같은 DB 를 가지고 있고 BFF 로 MSA 를 호출하는 환경을 생각해보자


BFF 는 A,B,C 를 생성할 수 있는 요청을 모두 받았고 이들을 각기 분리하여 A 서비스, B 서비스, C 서비스로 전달하였다. 이때 A, B, C 의 ERD 는 다음과 같다.
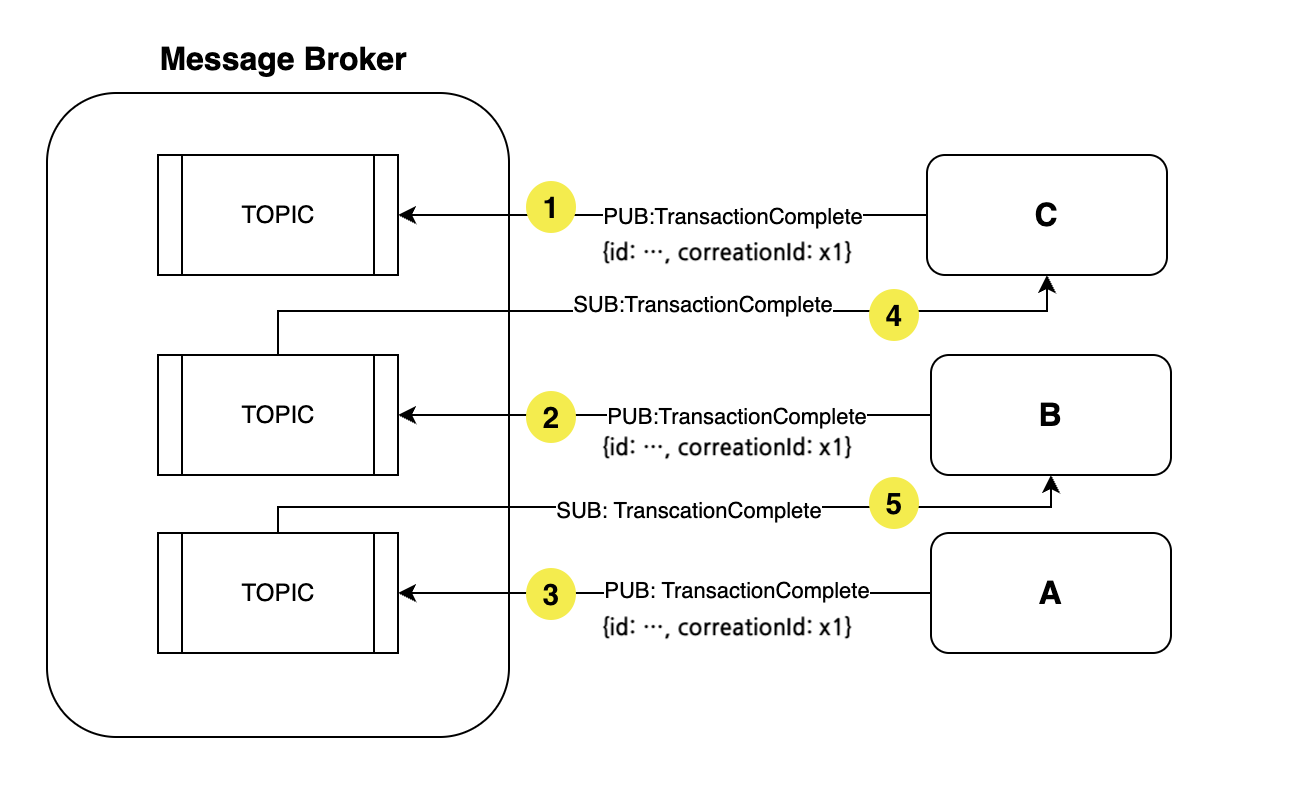
BFF 는 각 서비스의 순서를 모르게(결합도가 낮은) 설계 되었기 때문에 동시에 A, B, C 서비스를 호출하였고, 각각의 A, B, C 의 영속화 순서는 보장되지 않았다. 그 결과 C → B → A 순서로 영속화가 되었다. B 는 A의 id 를 알아야하고 C는 B 의 id 를 알아야 하지만 B 와 C 는 fk 가 누락된 상황이다.
각 서비스는 본인들의 영속화 업무가 끝나자 TransactionComplete 이벤트를 발행한다. 그 순서는 아래와 같다.

발생 이벤트의 payload 에는 생성된 엔티티의 id 만 담겨있다고 생각하면 B 는 A 가 생성되었다는 이벤트를 구독하여 확인했지만 도대체 이 A 를 어떤 B 와 연관시켜야 할지 알 지 못하며 C 역시 마찬가지다.
어떻게 해야할까? BFF 가 모든 paylaod 를 A 에게 넘기고 A는 영속화후 남는 payload 로 B 를 만들고, 다시 같은 작업을 B 는 C에 대해 반복해야할까? 이렇게 설계된다면 서비스간 결합도가 굉장히 높은 상태이므로 좋은 설계라고 볼 수 없다.
이때 등장하는게 correlationID란 개념이다. BFF 에서(혹은 API Gateway 에서) 각 요청을 고유하게 구분할 수 있는id 를 생성하여 각 서비스의 생성 요청에 함께 보내는 것이다. 그리고 각 서비스는 이벤트를 발행할때 생성된 엔티티의 id 와 이 유니크한 id 를 함께 payload 에 넣고 발행한다면 상호 결합도는 낮추면서 DB 의존 관계를 명확하게 유지할 수 있게 된다.
이러한 correlationID 를 적용하여 위의 이벤트 발행에 payload 를 붙여서 보여주면 다음과 같다.
5. 보장되지 않은 영속화 순서 , 아직 메시지를 받아들일 준비가 안됨...
이번엔 반대로 영속화 순서가 A -> B -> C 순서라고 생각해보자. 그리고 이런 경우에는 A 가 TransactionComplete이벤트를 발행해도 B 는 이 메시지를 구독하고도 처리할 준비가 되지 않았을 것이다. 이것은 C역시 마찬가지다.
주로 한국에서 많이 사용하는 kafka 에서 어떻게 처리할지 알아보겠다.
5.1 Kafka 에서 준비되지 않은 TransactionComplte 메시지 처리
이벤트를 소비했으나 연관관계를 매핑해줄 엔티티가 아직 없는 경우
- Kafka 는 메시지의 오프셋을 고의로 커밋하지 않는 것으로 메시지를 유지할 수 있다. 그리고 N 초 뒤에 다시 메시지를 소비한다.
- 이벤트를 Dead Letter Queue 에 저장하고, 엔티티 B 가 영속화 되었을때 재처리하도록 할 수 있다.
- Fallback Storage 를 이용하여 TransactionComplete 이벤트를 임시 저장소(Redis, DB) 에 저장한 뒤 B 가 영속화된 뒤 재처리한다.
Python 코드로 보면 이렇다.
from kafka import KafkaConsumer, KafkaProducer
import json
import time
consumer = KafkaConsumer(
'transaction-events',
group_id='service_b',
bootstrap_servers='localhost:9092',
enable_auto_commit=False, # 오프셋 자동 커밋 비활성화
value_deserializer=lambda v: json.loads(v.decode('utf-8'))
)
# 임시 저장소 (Redis나 DB로 대체 가능)
temp_storage = {}
def handle_event(event):
correlation_id = event['correlation_id']
a_id = event['a_id']
# B 엔티티가 아직 없는 경우
b_entity = find_b_entity_by_correlation_id(correlation_id)
if not b_entity:
print(f"B entity not found for Correlation ID {correlation_id}. Retrying...")
temp_storage[correlation_id] = event # 이벤트를 임시 저장
time.sleep(5) # 대기 후 재처리
return False
# B 엔티티 업데이트
b_entity.a_id = a_id
save_b_entity(b_entity)
print(f"Updated B entity with A ID {a_id}")
return True
for message in consumer:
event = message.value
success = handle_event(event)
# 성공적으로 처리된 경우만 오프셋 커밋
if success:
consumer.commit()
'기초 지식 > MSA' 카테고리의 다른 글
| MSA 주요 패턴: 중앙화된 로그 집계 패턴 (0) | 2024.11.27 |
|---|---|
| MSA 전환을 위한 서비스 분리 전략 (1) | 2024.11.26 |
| MSA 주요 패턴: 서비스 디스커버리(Service Discovery) 패턴 (0) | 2024.11.20 |
| MSA 개념 (2) | 2024.11.20 |